


MySQL基础知识
规范
库
- 命名规范:驼峰
- 库名要能体现业务范围
表
- 命名规范:驼峰
- 表名称要能反映出功能
- 表必须要有注释
列
- 命名规范:小写字母
- 列名要能表达具体含义,比如shopid,userid
- 列的数据类型尽量选择整型,并且范围够用即可
- 列必须要有注释
索引
- 命名规范:普通索引 IX_<column1_column2,,,>,唯一索引 UK_<column1_column2,,,>
索引介绍
什么是索引
索引是存储引擎用于快速找到记录的一种数据结构
常见索引类型
BTREE,HASH,全文索引等
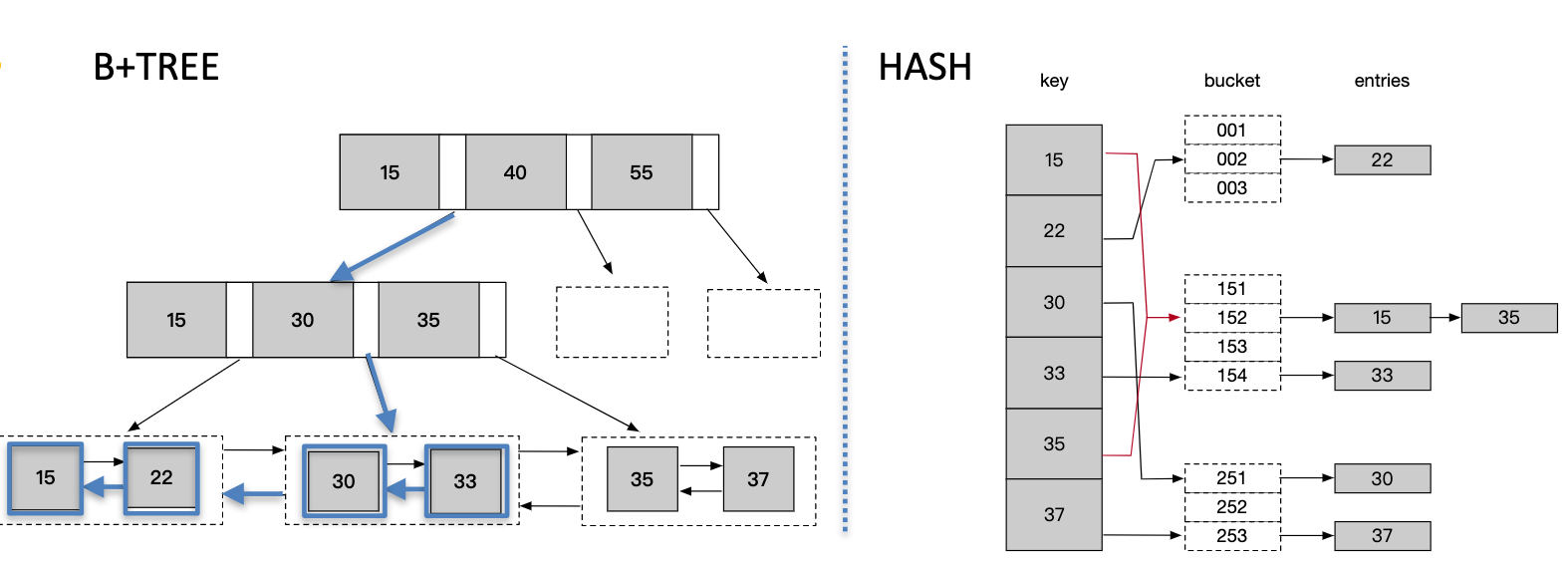

数据组织方式
聚簇,非聚簇
聚簇索引:表记录的物理存储顺序与索引顺序一致,且索引的叶子节点就是数据节点
非聚簇索引:表记录的物理存储顺序与索引顺序无关,叶节点包含主键值或指向数据块的
指针(因存储引擎而异,InnoDB存放主键和索引键值,MyISAM存放数据库指针)

索引如何设计
哪些列建议创建索引
WHERE, JOIN , GROUP BY, ORDER BY 等语句使用的列
利用最左前缀
(A, B, C):A, A&B, A&C, A&B&C, B, C, B&C
如何选择索引列的顺序
经常被使用到的列优先,利用最左前缀,尽量复用已有索引
区分度大的列优先,区分度 = distinct(col) / count(col) , distinct(col) 即cardinality,至少大于0.1,尽快排除掉更多的记录
宽度小的列优先,列宽度 = 列的数据类型,宽度越小,单节点的key值越多,索引树的高度越低,查询复杂度越低
字符集和校对集
定义
- 字符集 (Character sets)含义:
- 由一些列字符符号及其编码组成的集合。常见字符集:Unicode, Asian,West European等;
- 假设有A,B,a,b四个字母,有如下映射:A => 0, B=>1, a => 2, b =>3 其中A就是字符符号,0就是编码
如果比较A和B两个字符的大小,最简单的方法是比较二者的编码,即比对 0 和 1,由于 0 < 1,因此得到A < B。其中“比较字符编码” 就是一种比对规则。
- 校对 (Collations)含义:
- 一组用于某个字符集的比对规则。命名规则:以字符集的名字开头,以_ci,_cs或_bin结尾_ci 表示大小写不敏感、_cs表示大小写敏感_bin 表示按二进制编码值比较
- 常见字符集
- Unicode
- “点” ——> UTF8编码:0XE782B9 3字节
- “😊" ——> UTF8mb4编码:F09F9880 4字节
- Asian
- “点” ——> GBK编码:0XB5E3 2字节
- West European
- “A” ——> Latin1编码:0X41 1字节
- Unicode
https://dev.mysql.com/doc/refman/5.7/en/charset-charsets.html
查看命令
show character set;

show collation;

两者之间关系
- 字符集会有多个校对规则,并且有一个默认
- 校对规则只属于一个字符集
如何设置
MySQL字符集的设置有两个场景
- 创建对象(库、表、列)时,可显示指定所用字符集,也可通过继承关系获取
- 服务器和客户端通信时,服务器和客户端可能使用不同的编码,可通过配置,实现必要的转换
创建对象时
- 建库和建表时可以显示指定数据库、表或列的字符集
- 未指定时通过如下继承关系得到默认的字符集

服务器和客户端通信时
- 有如下3个变量控制通信时的字符集
- | 字符集变量 | 功能 |
| - | - |
| character_set_client | MySQL Server假定客户端对发送SQL语句时设置的字符集 |
| character_set_connection | MySQL Server接收客户端发布的查询请求后,将其统一转换成该字符集,之后交由服务器内部处理 |
| character_set_results | MySQL Server将结果集和错误信息返回给客户端时设置的字符集 | - 连接时指定
- 终端:mysql --default-character-set=字符集-u root -p
- JDBC:URL=jdbc:mysql://localhost:3306/testdb?useUnicode=true&characterEncoding=字符集
- 运行时指定
- SET character_set_client = utf8 或SET names utf8,同时设置3个变量的值为utf8
运行图

一般我们常会遇到的问题就是emoji表情😊的字符集utf8mb4,大小写的校对集utf8mb4_bin
分库分表
什么是分库分表
- 分库:把原本存储于一个库的数据分块存储到多个库上
- 分表:把原本存储于一个表的数据分块存储到多张表上
为什么要分库分表
- 单库资源有限,会影响应用性能,阻碍业务发展
- 业务场景拓展,数据写入和查询频次增加,IO资源不够,导致性能下降
- 业务数据增加,磁盘和内存资源遇到瓶颈,比如无法新增表,无法创建索引等
- 单表数据过大,同样影响增删改查性能
- 索引高度增大,IO增加,索引维护复杂
何时分库分表
| 指标 | 阀值(版本<=5.7.21) | 阀值(版本>=5.7.22) |
|---|---|---|
| 单库容量 | 300GB | 300GB |
| 单表数据量 | 60GB | 60GB |
| 单表行数 | 最佳1000W内,不能超过2亿 | 最佳1000W内,不能超过2亿 |
| 单库单表写QPS | 4K | 7K |
| 单库单表读QPS | 40W | 60W |
如何分库分表
-
垂直拆分
将表按照功能模块、关系密切程度进行划分,部署到不同的库上;比如将评价表和评价带图表划分到一个库,比如将门店信息表中字段拆分到不同表。
-
水平拆分
当一个表中的数据量过大时,可将该表的数据按照某种规则分散到多张表上,或者将这些表分散在多个库上
拆分策略
分表策略
-
哈希:哈希取模路由
举例:一般选择业务查询的主体标识作为key,比如userid
优缺点:数据分布均匀,请求散列均匀,不易出现热点访问,扩容困难
-
range:根据业务查询的主体ID进行划分
举例:userid范围1-10000在表1,10001-20000在表2...
优缺点:分表数据量可控,最终会会平衡,扩容方便,但存在热点访问问题
-
时间:根据数据的生产的时间进行划分
举例:时间在1月份的在表1,2月份的在表2...
优缺点:扩容方便,但分表数据量不可控,也容易造成热点访问问题
分库分表数量
假设有如下ABCD数值:
A:预估3到5年的总记录数
B:单条记录大小(Byte)
C:单表建议记录数(小于1KW,不要超出2亿)
D:单库建议容量(小于300GB)
则获得相应的计算结果为:
分库数:A * B / D /1024/1024/1024(取最接近2的N次方的数,建议向上取)
分表数:A / C(取最接近2的N次方的数,建议向上取)
单库分表数:分表数/分库数
全局主键生成策略
部分场景需要做数据的合并,要保证一条记录全局唯一,比如表进入hive时
| 生成策略 | 优点 | 缺点 |
|---|---|---|
| UUID | 本地实现,低延迟 | ID过长(128位),浪费存储空间 |
| 数据库自增ID | 实现简单,成本低 | 有单点,容易产生性能瓶颈,分布式集群模式下不适合 |
| Snowflake | 分布式生成,无单点问题 | 可能出现重复ID,数据间隙较大 |
| Leaf | ID为64位正整数,SLA有保障 | 非递增关系,不能作为分布式索引 |
案例
| 库表 | 历史数据 | 日增量 | 3个月数据量 | 单条记录大小(byte) |
|---|---|---|---|---|
| 待点评表 | 9亿4千万 | 1000万 | 118亿9千万 | 394B |
拆分方法:水平拆分
分表策略:按userid哈希
分库分表数:
- 分库数:118亿9千万 * 394/1024/1024/1024/300 ≈ 14.5,取16
- 分表数:118亿9千万 / 1000万 = 1189
- 单库分表数: 1189 / 16 ≈ 74,应取128,实际选取了64






