MySQLExplain执行计划及调优策略
Explain关键字解读
案例表:评价表Dp_Review
| 字段 | 含义 |
|---|---|
| reviewid | 评价的ID,自增主键 |
| reviewbody | 评价的文本内容 |
| userid | 写评价的用户 |
| shopid | 评价绑定的商户 |
| power | 评价的状态 |
| rank | 评价的排序分值 |
| addtime | 评价创建的时间 |
| lasttime | 评价更新的时间 |
| 索引 | 支持的场景 |
|---|---|
| IX_DP_Review_AddTime | 按评价创建时间排序 |
| IX_DP_Review_ShopID_AddTime | 取商户评价,并按创建时间排序 |
| IX_ShopID_Rank | 取商户评价,并按质量分排序 |
| IX_DP_Review_ShopID_Power_LastTime | 取商户有效评价,并按更新时间排序 |
select_type
表示select语句的查询类型
-
SIMPLE:表示简单的查询,不使用UNION或者子查询。
-
PRIMARY:最外层有SELECT
explain select * from (select * from Dp_Review where reviewid=1)b; -
UNION:第二层,在SELECT之后使用了UNION。
explain select * from Dp_Review where reviewid=1 union select * from Dp_Review where reviewid=2;
-
SUBQUERY:子查询中的第一个SELECT。
explain select * from user where userid =(select userid from Dp_Review where reviewid=1);
type
表示查询连接的类型(the join type)。它描述了找到所需数据使用的扫描方式
- const、system:最多一个匹配行,使用主键或者unique索引
- system一般出现在表只有一行,且出现在MyISAM引擎

- eq_ref:返回一行数据,通常在联接时出现,使用主键或者unique索引
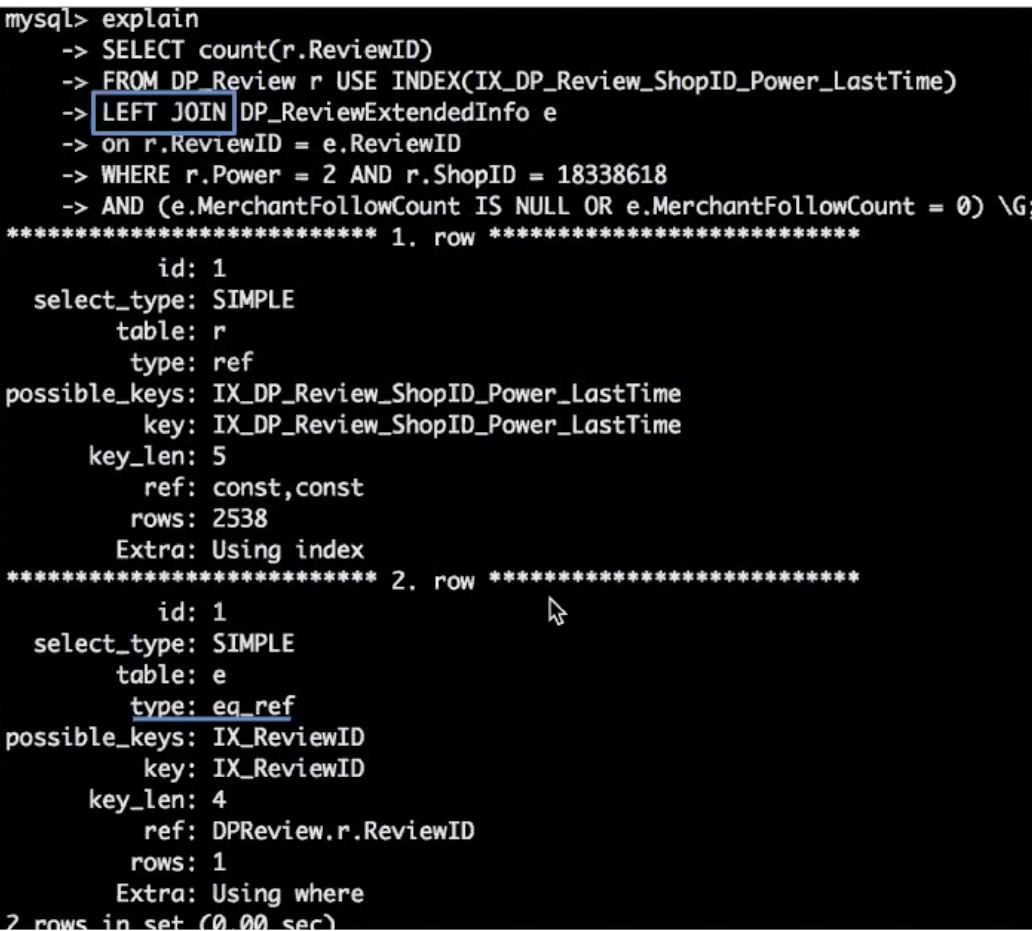
- 比如主表和扩展表通过主键关联查询,扩展表的type就是eq_ref
- ref:使用索引的最左前缀,且索引不是主键和unique索引
- range:索引范围扫描,对索引的扫描开始于某一点,返回匹配的行

- 大于、小于、等于、between and 、in 等范围查询都是range
- 范围查询涉及到遍历和排序
- 线上的查询尽量都在range以上
- index:以索引的顺序进行全表扫描,优点是不用排序,缺点是还要全表扫描,线上尽量避免

- 比如没有任何的where条件,根据group by分组排序
- all:全表扫描,必须避免


possible_keys
显示本次查询可能使用到的索引
Key
优化器决定采用哪个索引来优化对本次该表的访问,可通过use index给出建议,key避免不能null
key_len
使用的索引左前缀的长度(Bytes),亦可以理解为索引了索引的哪些字段
- 定长字段:
- int占4个字节、date占3个字节、timestamp占4个字节
- char(n)需要[n * 上编码字符所占字节],如utf8编码,则长度为n * 3个字节,utf8mb4编码,则长度为n * 4个字节
- ALLOW NULL的字段:需要额外增加1个字节来标记是否为null,mysql在优化的时候也没办法对allow null的字段进行优化
- 变长字段varchar(n):需要[n * 编码字符所占字节数 + 2]个字节,额外2个字节用于记录长度
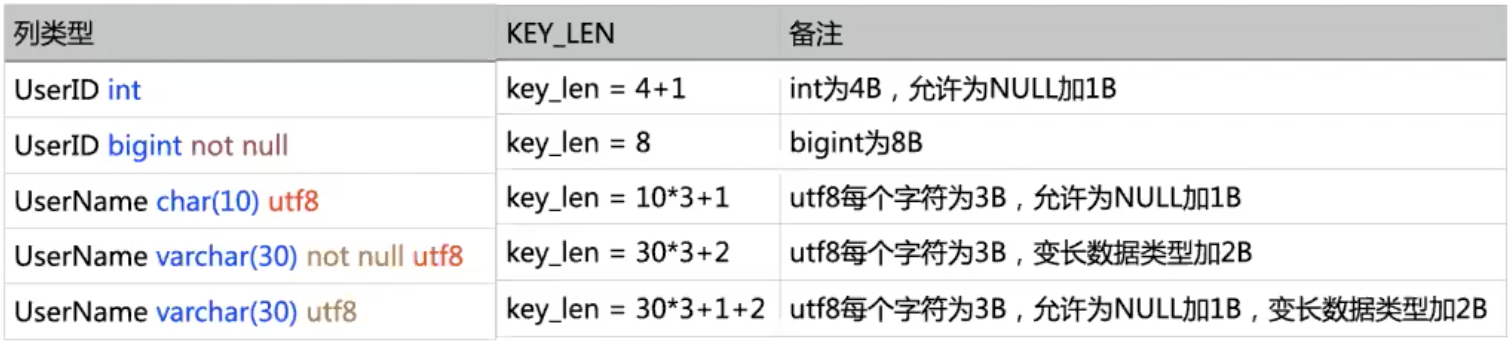
- 不损失精确性的情况下,key_len越小越好,索引越小,索引健值越小,所以的每个节点存储的关键词的个数就越多,也就是B+Tree分的路数就越多,树的高度就越低,查询性能提高用不到字段移除
ref
表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值,如果是使用的常数等值查询,这里会显示const,如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段,如果是条件使用了表达式或者函数,或者条件列发生了内部隐式转换,这里可能显示为func
rows
MySQL估算的为了找到所需的记录而需要检索的行数,作为优化器选择Key的参考,rows越小越好
filtered
这个字段表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例,注意是百分比,不是具体记录数。这个字段不重要
Extra
是否进行了额外的操作
- using index:索引覆盖,查询时只用到索引即可,不需要读取数据块
- innodb引擎主键索引叶子节点存的是数据,辅助索引叶子节点存的是索引列值以及PK,查询的内容在辅助索引就可以拿到不需要回表
- using index condition:是索引查询的下推,存储引擎完成了执行引擎的过滤
- 如果表中有三个字段a、b、c建立联合索引,查询的时候条件中没有b,只有a、c,一般存储引擎在检索数据的时候按索引最左匹配原则会将a字段条件筛选出的结果返回给执行引擎,但此时存储引擎会再对结果集还进行了c字段条件的过滤,跳过了联合索引中间的b字段,此时再将数据返回给执行引擎,那这样就会出现using index condition
- using where:在存储引擎返回记录后执行引擎根据where其它条件再做过滤
- using temporary:使用临时表,通常在使用group by,order by出现
- 存储引擎将数据返回给执行引擎,如果顺序不是期望的顺序,需要暂存结果集进行排序,暂存方式有两种,如果内存够用,就内存中排序,如果内存不够用,就会创建一个临时表,再进行外排,此时就会出现using temporary;表关联也会出现,A和B关联再和C关联,A和B关联的结果会创建一个临时表,把这个临时表再和C关联;所以在关联的时候会出现using temporary,在结果集的排序时也可能会出现
- 临时表的创建和访问都会造成性能损耗,浪费存储空间,尽量不要出现
- using firesort:用到非索引顺序的额外排序,当order by未用到索引时发生
- 可能是内存排序,也可能是外排,取决于sort buffer的大小,当额外的排序使用的是外排就会造成性能损耗,需要避免
优化思路及案例
思路

案例

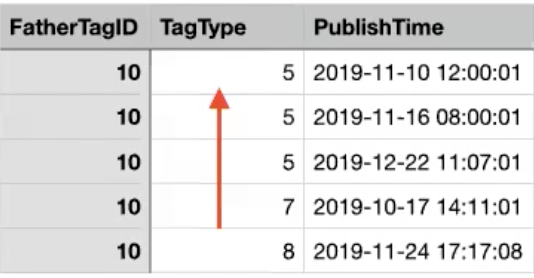
需求:查询美食品类视频,结果按标签分类和发布时间排序
explain
select VideoID from TagVideoIndex
where FatherTagID=10 order by TagType , PublishTime \G;
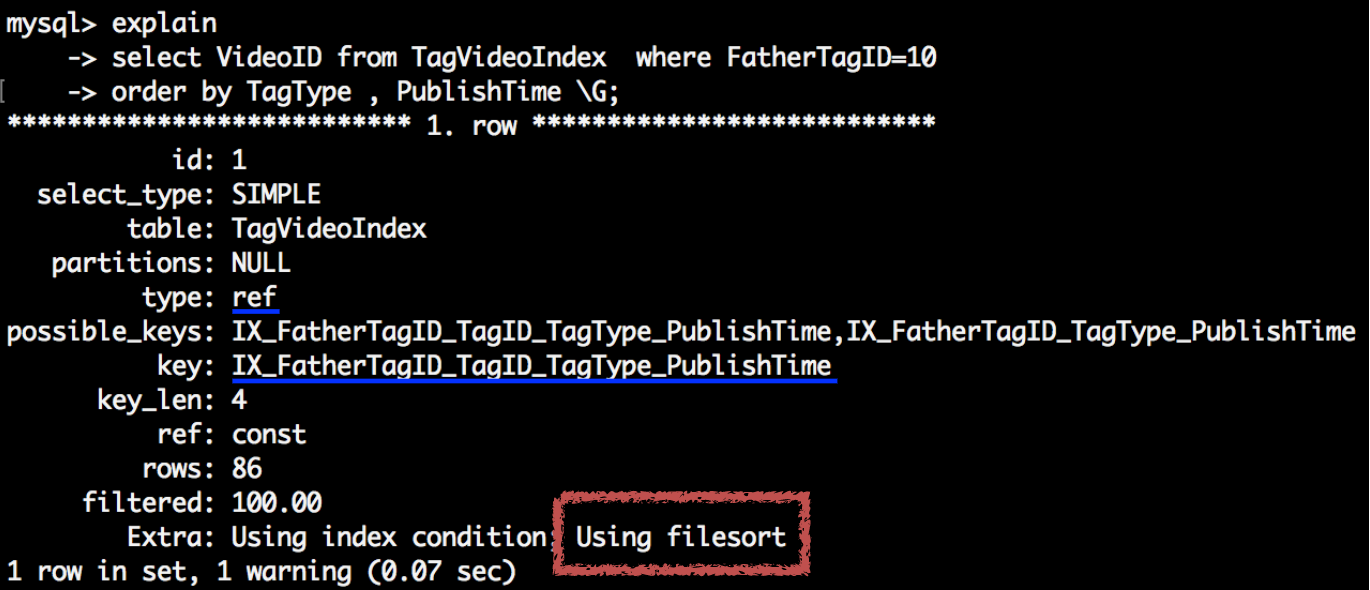
可以看到执行计划Extra显示使用了Using filesort,说明执行引擎进行了额外的排序,因为用的索引是第一个带TagID的索引,按最左匹配原则存储引擎没有根据TagType排序。那为什么不是用第二个索引呢,我们使用force index 强制优化器使用IX_FatherTagID_TagType_PublishTime再来看执行计划
explain
select VideoID from TagVideoIndex force index (IX_FatherTagID_TagType_PublishTime)
where FatherTagID=10 order by TagType , PublishTime \G;
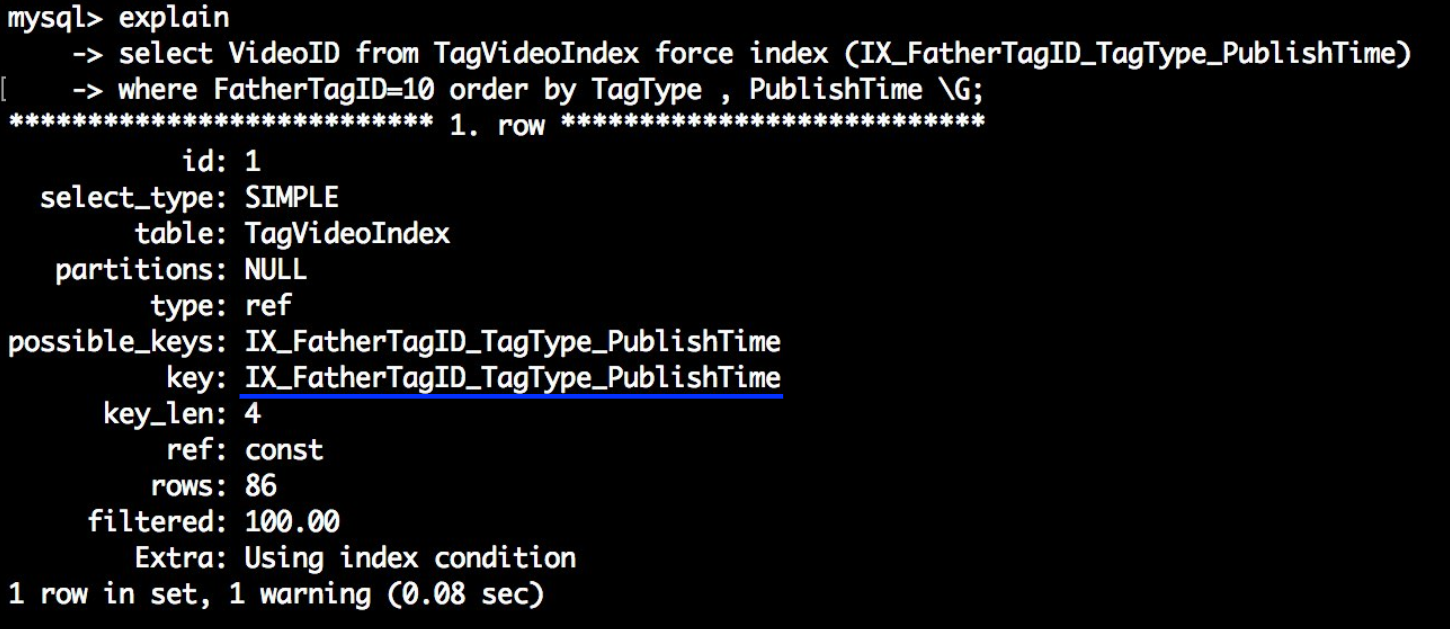
我们可以看到此时Extra 没有了Using filesort,那为什么优化器会选择第一个索引,原来发现两次执行的查询所扫描的行数都是86条,对于优化器而言,扫描的行数都是一样的就随机选择了一个,对于存储引擎是没问题的,但是数据传给执行引擎的时候需要进行额外排序,线上不要轻易使用,因为当扫描行数发生变化时可能这不是最优的索引,要进行权衡考虑
那此时如果对PublishTime进行倒序排序又会是什么效果
explain
select VideoID from TagVideoIndex force index (IX_FatherTagID_TagType_PublishTime)
where FatherTagID=10 order by TagType , PublishTime desc;
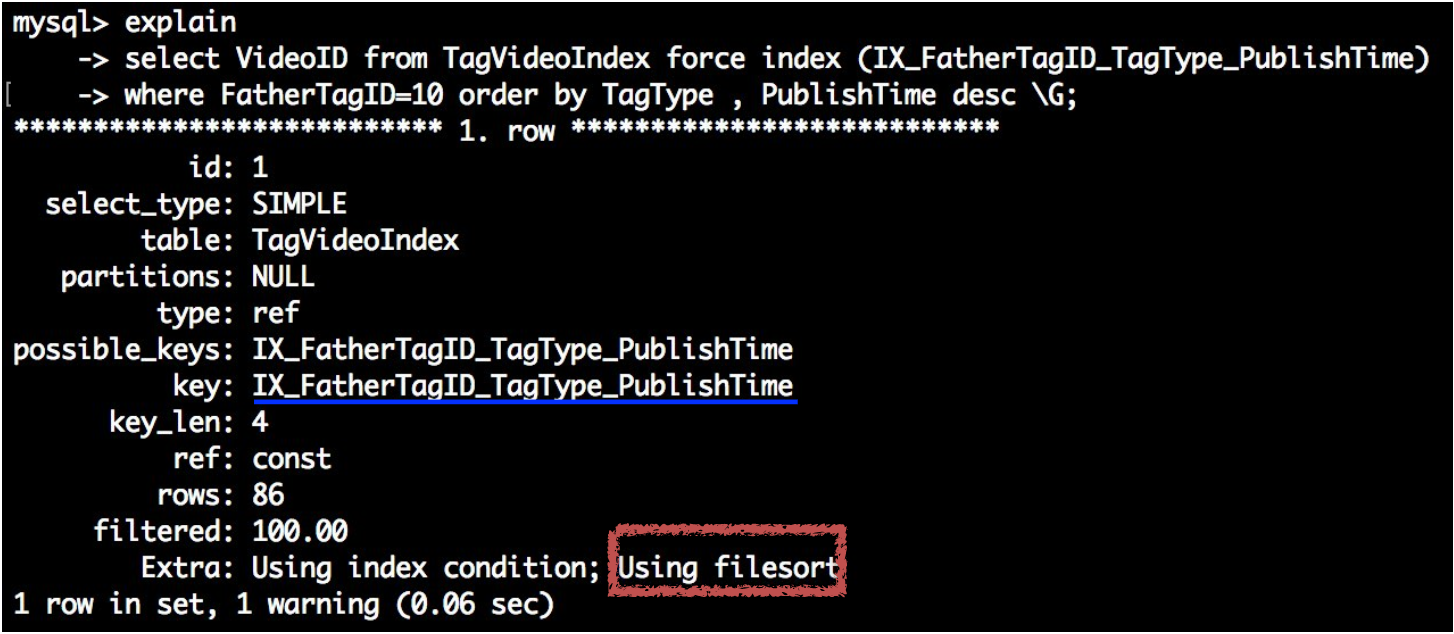
发现此时又出现了Using filesort,这是因为创建联合索引的时候,索引树的关系就是按照TagType 正序 PublishTime正序的创建,此时执行引擎要负责对PublishTime进行额外的排序
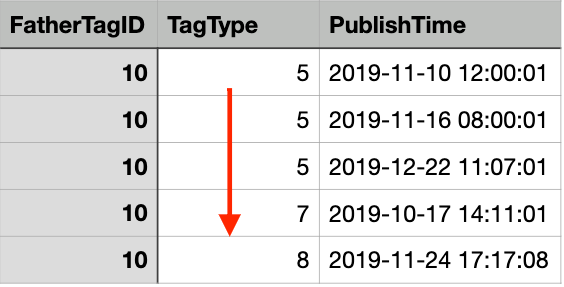
那此时我们如果创建一个按TagType正序,按PublishTime倒序的B+树索引,再来查看执行情况
create index IX_FatherTagID_TagType_PublishTime_Desc
on TagVideoIndex (FatherTagID, TagType, PublishTime desc);
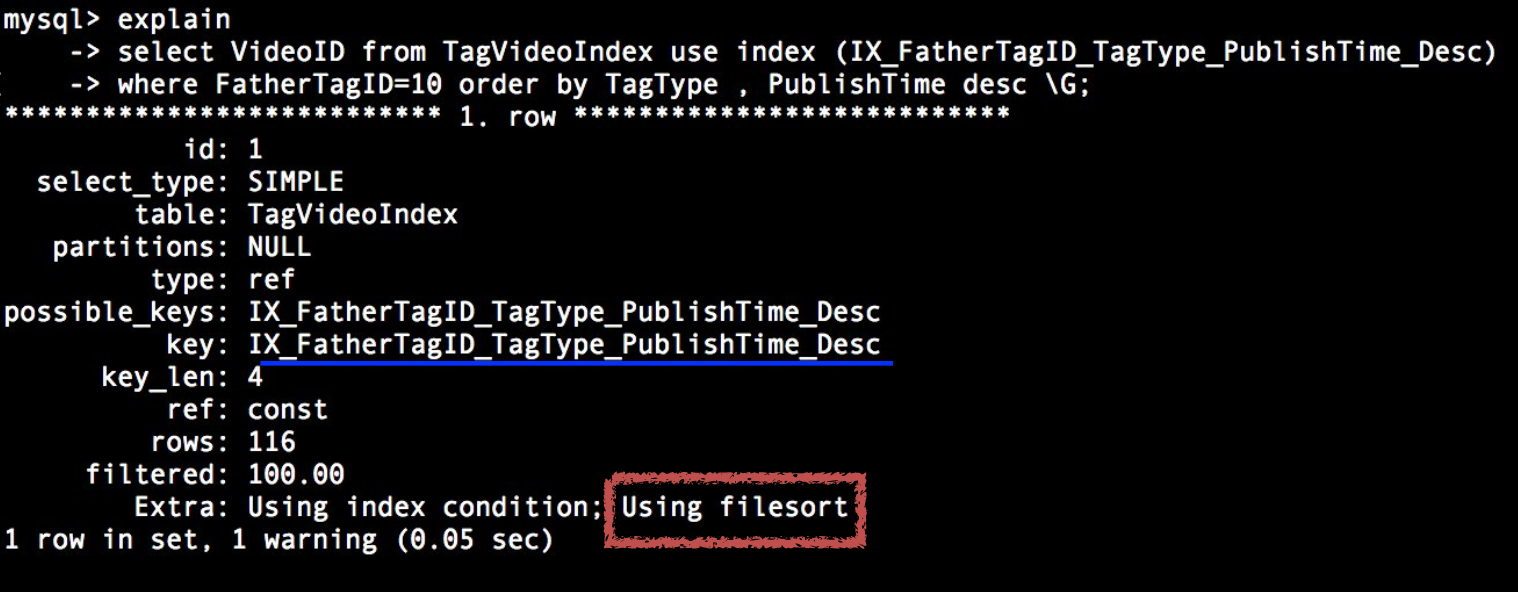
可以看到,索引确实是使用到了新创建的索引,但是还是出现了Using filesort,这是因为现在所使用的版本创建索引虽然支持设置Desc语法,但8.0之前的版本会将次设置忽略,都按升序排序,那这个方案就不行了,此时我们该如何做呢?
- 如果是整形值,则考虑存储对应的负值,增加一列
- 和产品协商排序规则,对TagType也进行倒序排序,我们再来看执行计划
explain select VideoID from TagVideoIndex use index (IX_FatherTagID_TagType_PublishTime)
where FatherTagID=10 order by TagType desc , PublishTime desc \G;
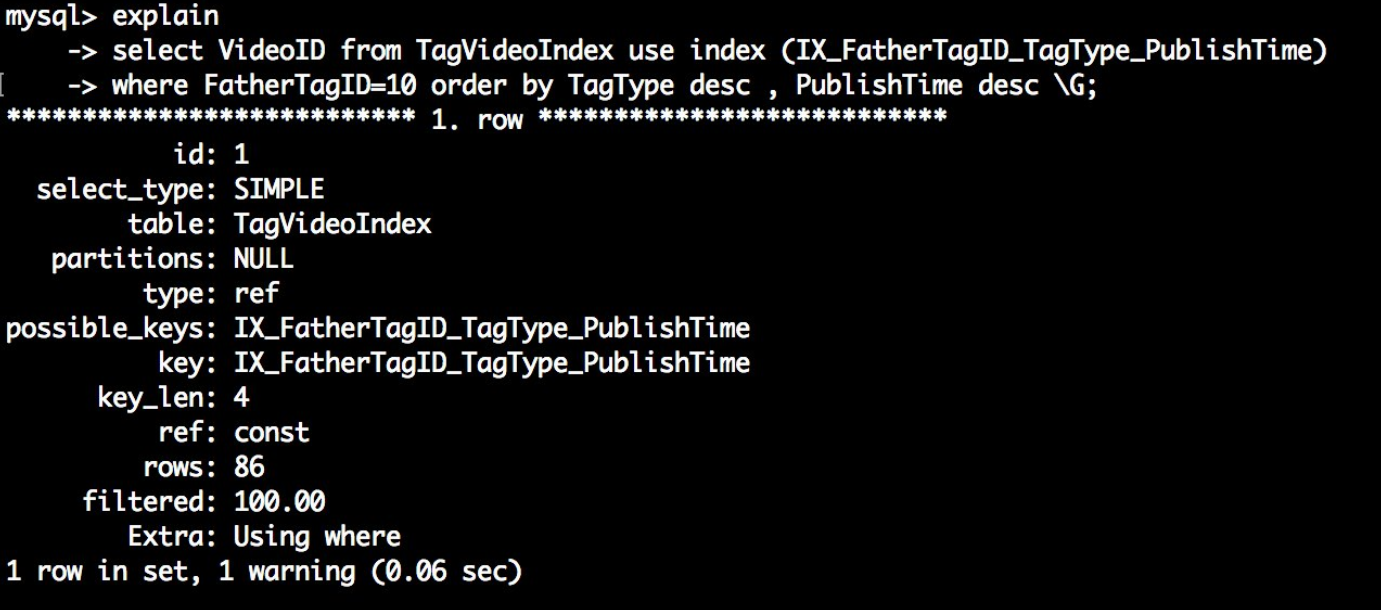
发现此时已经没有出现Using filesort了,因为存储引擎检索出来的数据都是进行倒序排序,执行引擎就不需要进行额外的排序了