kimi-k2.5 为何能屠榜(国货之光)
一、大模型训练过程回顾
1、文本大模型训练
数据语料先通过 BPE 算法分词得到文本 Token(1 个 token ≈ 1.2–1.5 个汉字),再通过 词汇表(Vocab) 映射为数字 ID,数字 ID 经过 Embedding 层转换成向量,最后输入 Transformer 模型进行训练。
2、多模态大模型训练
大多数多模态大模型采用先文本预训练、再多模态对齐、最后对齐微调的范式:
- 先在大规模文本语料上预训练得到文本大模型基座;
- 引入视觉编码器,将图像映射为视觉特征序列(语音信息可通过 ASR 模型如 OpenAI 的 Whisper 转换成文本或语音特征),并与文本 token 拼接,进行多模态预训练,实现图文 / 音文语义对齐;
- 再通过 SFT(监督微调)与 RLHF/DPO(人类偏好对齐)等阶段,让模型输出更符合人类交互习惯。
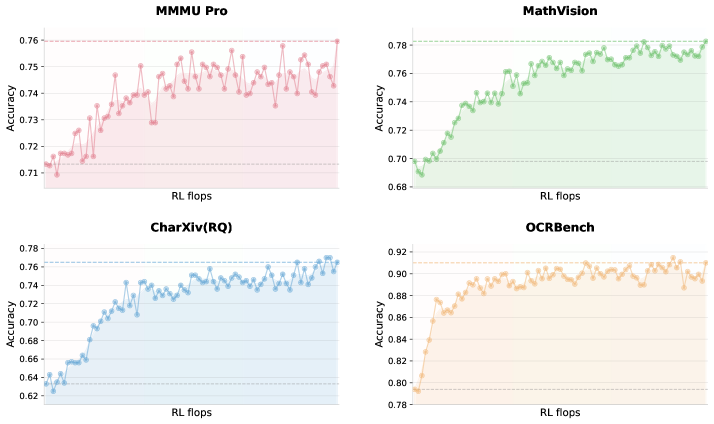
二、kimi-k2.5 效果
各基准榜单:https://arxiv.org/html/2602.02276v1
OpenClaw 测评:kimi-k2.5 各项指标都排在前列
https://pinchbench.com/?score=average


三、kimi-k2.5 训练过程
https://arxiv.org/html/2602.02276v1

从预训练阶段就一起进行,且语料比是1:9,通过 IPython 结合提升多模态的能力。

1、零视觉监督微调(Zero-vision SFT)
预训练的 VLM 不自然地执行基于视觉的工具调用,这对多模态强化学习构成了冷启动问题。传统方法通过手动注释或提示工程的思维链(CoT)数据来解决这个问题 [7],但此类方法的多样性有限,常将视觉推理限制在简单的图表和原始工具操作(裁剪 、 旋转 、 翻转 )上。
观察到高质量的文本 SFT 数据相对丰富且多样化。我们提出了一种新颖的方法——零视觉 SFT,仅使用文本 SFT 数据在训练后激活视觉和能动能力。在这种方法中,所有图像处理都通过 IPython 中的程序化操作代理,有效地作为传统视觉工具使用的推广。这种“零视觉”激活使得多样化的推理行为得以实现,包括通过二值化和计数来估算物体大小等像素级操作,并推广到视觉基础任务,如物体定位、计数和光学字符识别(OCR)。
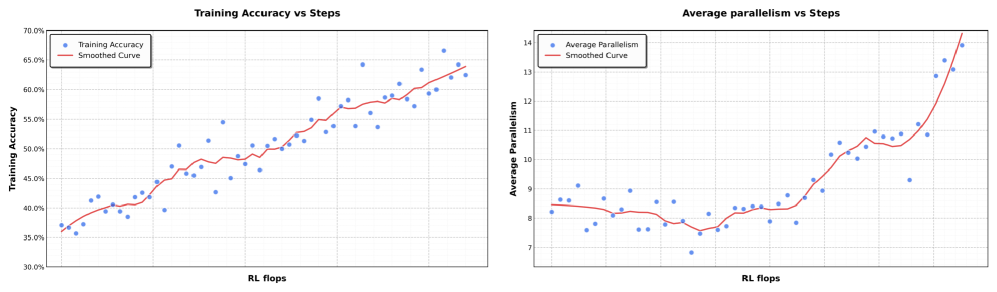
下图展示了强化学习训练曲线,起点来自零视力 SFT。结果表明,零视觉 SFT 足以激活视觉能力,同时确保跨模式的泛化。这一现象很可能是由于文本和视觉数据的联合预训练所致,与零视觉 SFT 相比,我们的初步实验显示,文本视觉 SFT 在视觉和能动任务上的表现明显差,可能是因为缺乏高质量视觉数据。
2、Agent Swarm 特工蜂群
现有基于 Agent 的系统面临的主要挑战在于其依赖于顺序执行推理和工具调用步骤。虽然这种结构对较简单、短期任务可能有效,但随着任务复杂度增加和积累的上下文增长,这种结构就变得不够充分。随着任务发展为包含广泛信息收集和复杂多分支推理的过程,顺序系统常常遇到重大瓶颈 [6, 4, 5]。 单个代理逐步完成的能力有限,可能导致实际推理深度和工具调用预算耗尽,最终阻碍系统处理更复杂场景的能力。
为此,引入了代理群组和并行代理强化学习(PARL)。K2.5 不像推理链一样执行任务或依赖预设的并行化启发式,而是通过动态任务分解、子代理实例化和并行子任务调度来启动代理群组。重要的是,并行性并不被假定为固有的优势;关于是否、何时以及如何并行化的决策,通过环境反馈和强化学习驱动的探索明确学习。如下图所示,性能的进展展示了这种适应能力,随着编排器在整个训练过程中优化并行化策略,累计奖励会平滑地增加。